用 Python 从多个文件中提取信息并汇总
本文最后更新于:几秒前

谷月姐最近需要对所有博客文章进行统计整理。每篇博文的源代码开头都有一段 YAML 代码,存储了这篇文章的一些信息。我的需求是:把每篇博文开头 YAML 代码中的 date 和 banner_img 字段连同它们的数据一起提取出来,汇总到同一个 CSV 文件,便于后续用 Excel 分析。
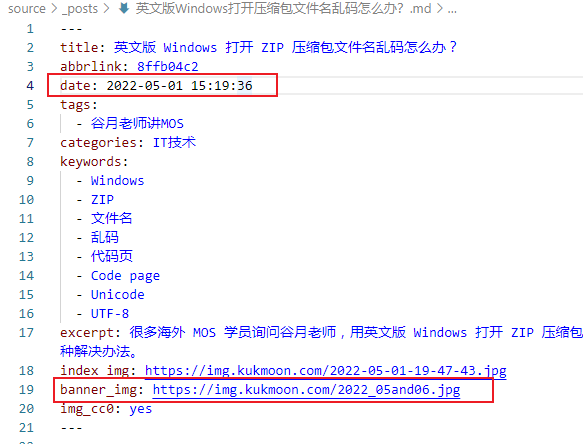
博客有 100 多篇文章,如果手工操作,要重复 100 多次。还是编程解决更方便一些。
我从来没学过 Python,为了完成这项要重复 100 多次的工作,在谷歌、知乎和 CSDN 的帮助下,现学现卖,硬是通过复制粘贴网上的代码,写了一个 Python 程序。这是我第一个 Python 程序。
1 | |
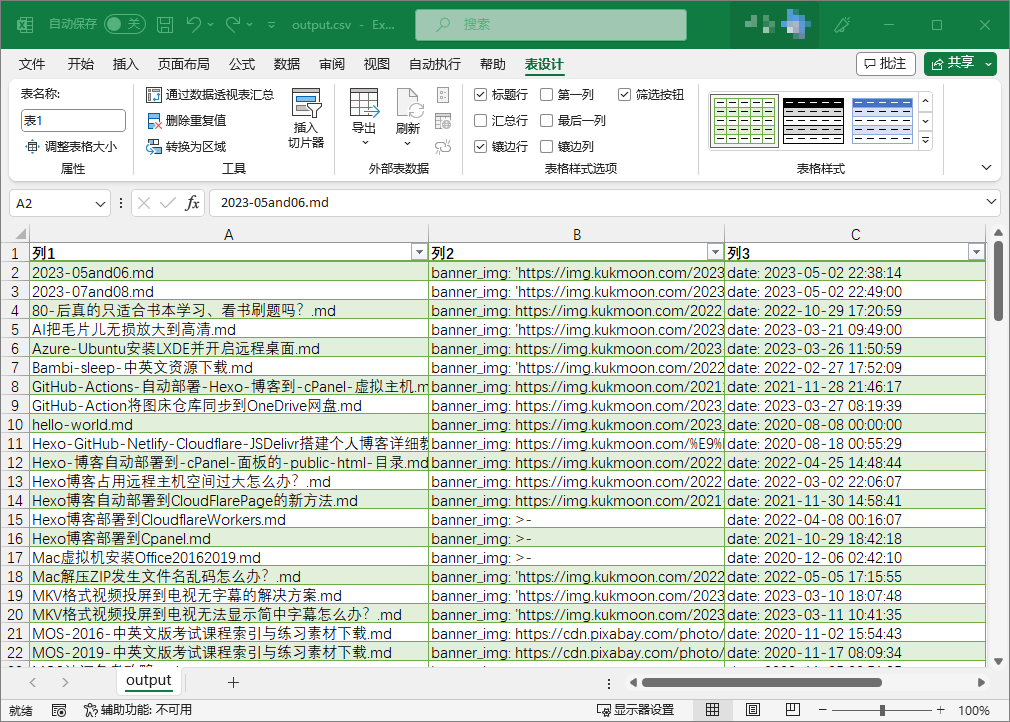
然后,用 Excel 打开生成的 CSV 文件,如图所示。
图片版权
题图:Image by macrovector on Freepik。
头图:该图片由 David Mark 在 Pixabay 上发布。
求扫码打赏
“我这么可爱,请给我钱 o(*^ω^*)o”


用 Python 从多个文件中提取信息并汇总
https://blog.kukmoon.com/e23eceac/